![]()

![]()
|
|
|
Rx de un Compilador.
Por Gustavo Daniel Yapura
Este Documento esta disponible en formato Word 97 el ftp de la UTN Facultad Córdoba en
ftp://ftp.frc.utn.edu.ar/pub/BBS/Documentos/Labsis/rxc.doc
Introducción:
En un mundo informatizado como en el que vivimos, en el que cada día que pasa dependemos más y más de un sistema informático eficiente, el cual debe estar preparado para brindarnos la más alta calidad de servicios y prestaciones. Además de ser sencillo en su manejo y sobre todo confiable, siendo estas características indispensables para el usuario final. Quien no se fija, ni pregunta como se realiza determinada tarea, pero si es buen critico a la hora de ver resultados, pero hay otros que contrarios a estos, se hace la pregunta del millón, "¿Cómo se logra hacer tal y tal cosa? ,"¿Cómo es posible que un graficador trabaje tan rápido?, ¿Cómo es posible que un procesador de palabra a la hora de usar un diccionario sea tan eficiente?, ¿Cómo es posible llevar los resultados de una aplicación a otra?, o ¿Cómo es posible que un programa que fue creado por una empresa puede trabajar con los datos de obtenidos de otro programa, echo por otra empresa?. Muchas pueden ser las respuestas, algunos argumentaran que es el sistema operativo, otros dirán que son las normas y estándares establecidos, otros dirán irónicamente que es más sencillo de lo que se piensa, dirán que se hace clac con la rata aquí, se arrastra y se lleva a donde se quiere. Todos ellos tienen razón, sin embargo si indagamos mas a fondo. Surgirán preguntas más directas como por ejemplo "¿Cómo se logra tal velocidad, con tan buen manejo de gráfico?", claro que a todas ellas se puede responder diciendo, que todo se logra gracias al Hardware, y no estaríamos totalmente errados, porque un buen Hardware conlleva a un buen resultado, a una buena calidad de impresión en caso de volcado al papel, una buena imagen si hablamos de gráficos, o un buen tiempo de respuesta a la hora de realizar algún calculo matemático, pero siempre el Hardware será una parte, solo una parte.
Es en este punto donde surge el Software, los programas, o como el modismo denota hoy en día, las aplicaciones. Es decir que para obtener un buen resultado no solo hace falta un buen Hardware acorde a los requerimientos de la tarea que se quiere realizar, sino que calidad, eficiencia, velocidad, y confiabilidad hoy en día son sinónimos de un buen trabajo en conjunto de la dupla Hardware y Software. Dejando de lado lo que es el Hardware, y profundizando lo que representa su par, palabra ya adoptada en nuestro idioma, y muy usada en el mundo de la informática, deducimos que para obtener un buen software, ante todo esta el aspecto creador de quien lo realiza, luego hay que ver cual será el entorno de trabajo en que actuara, cuales serán los requerimientos del mismo, hay que saber elegir que paradigma de programación se usara.
Después de formuladas estas preguntas y de haber respondido a las mismas de manera apropiada. Hay que elegir cual es el lenguaje de programación más conveniente para realizar dicha tarea. Y cuando digo lenguaje me refiero a la definición del mismo según el diccionario de la real academia española, " lenguaje. m. Conjunto de sonidos articulados con el que el hombre manifiesta lo que piensa y lo que siente. 2 lengua sistema de comunicación y expresión verbal propio de un pueblo o nación, o común a varios..." si nos detenemos a analizar esta definición dentro del ámbito de la informática, veremos que no se puede aplicar la misma en su totalidad. Pues bien, primero que nada, para que halla comunicación deben existir por lo menos dos partes, si decimos que una de ellas es el ordenador y la otra el hombre, vemos que solamente una de ella cuenta con la capacidad del poder hablar, (hago notar que me refiero al hombre), mientras que la otra parte, el ordenador, si bien podría llegar a hablar con un "Hardware apropiado" y por supuesto con el correspondiente "software" capaz de manipular dicho hardware. Pero no nos salgamos del tema, si seguimos nuestro análisis descubrimos que en la segunda parte de esta definición hay un pequeño trozo de la misma que tiene mas sentido para nosotros lo informáticos, " sistema de comunicación y expresión...", si nos fijamos en la sección 7. Informática, del mismo diccionario encontramos lo siguiente " Conjunto de signos y reglas que permite la comunicación con un ordenador", podríamos decir entonces que un lenguaje de programación es un sistema de comunicación y expresión, que utiliza signos y reglas que permiten la comunicación entre un hombre y un ordenador".
Un lenguaje de programación o más genéricamente de computación, es el medio por el cual el hombre interactua con un ordenador. Pero el lenguaje de computación no es lo único que se necesita para que se produzca la comunicación, hace falta otro componente importante para completar el medio de comunicación, y es en este punto donde surge la palabra "interprete", cuya definición dice "persona que explica a otra en lengua que entienda" en el ámbito informático, olvidémonos por un instante de la palabra persona, e "interpretemos" su significado. Se puede decir entonces que a través de un interprete podríamos pedir a un ordenador que realice una tarea determinada sin preocuparnos de los detalles. Claro que este interprete no es más que una aplicación (programa), que realiza la traducción de lo que pedimos que comunique a un ordenador, por lo tanto un interprete es capaz de conocer dos lenguajes el del emisor y el del receptor.
En el mundo de la informática existen muchos lenguajes de programación, que trabajan con uno o varios paradigmas de programación (estilos, formas, métodos de programación), por lo tanto es de suponer que existen distintas reglas de sintaxis y semántica para cada lenguaje de programación como lo existe en cualquier otro lenguaje, sea cualquiera el tipo y contexto al que pertenezca. En tiempos ya muy remotos según cuentan los que saben proliferaban los interpretes, quienes tomaban la petición del usuario (hombre) e "interpretaban" la misma y se la comunicaban al ordenador quien la ejecutaba, y esperaba una nueva petición. La petición era declarada dentro los parámetros de definición del lenguaje usado. Con el tiempo se vio que el estar realizando una interpretación y traducción cada vez que se necesita realizar algo era poco efectivo, en cuanto a tiempo de trabajo del Hardware se refiere, y más aun si se trataba de un conjunto grande de instrucciones (peticiones), es aquí donde entraron en juego los compiladores, quien al igual que sus antecesores realizan una traducción de los programas (conjunto de intrusiones de un lenguaje) revisando que este dentro del marco de definición del lenguaje de programación utilizado. Con la diferencia que la traducción se realiza una sola vez y de todo el programa.
Después de todos estos tópicos previos, podemos decir que la calidad de un buen software es producto de un lenguaje de computación versátil, flexible y veloz, todo sinónimo de buen compilador, claro sin dejar de lado la capacidad creadora del programador (usuario, nosotros).
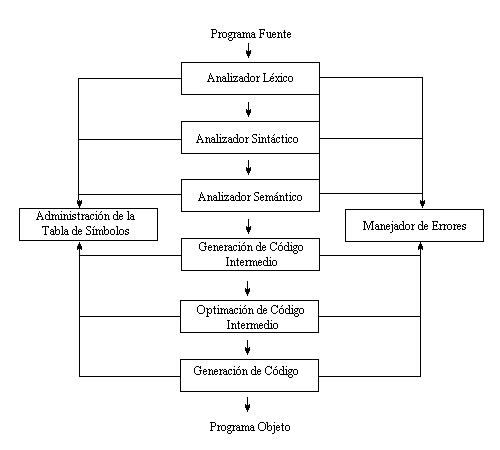
"¿Cómo funciona un compilador? ", es la pregunta de todo aquel que se hace llamar programador, a grandes rasgos un compilador toma un programa escrito en un lenguaje de programación con una gramática, sintaxis y semántica definida, revisa que este dentro de las pautas de definición del lenguaje, y lo traduce en programa de salida escrito en lenguaje binario, el cual es entendido por el ordenador y por lo tanto puede ser ejecutado por el mismo (recordar que un interprete a diferencia de un compilador no traduce todo el programa sino que va realizando la traducción e interpretación de la misma paso a paso, sin crear ningún programa de salida ejecutable). Las partes del proceso de compilación se dividen en dos: una llamada fase de Análisis y otra llamada fase de Sintaxis, las cuales interactuan entre si para la creación de la tabla de símbolos y el control del manejador de errores, dentro del análisis hay tres etapas llamadas análisis lexicográfico, análisis sintáctico, análisis semántico. Dentro de la fase de Síntesis existen las etapas de generación de código intermedio, optimización de código intermedio, y generación de código.
Al tener que describir como funciona un compilador tenemos que tener en claro en no confundir los términos compilador y compilación, se debe entender que al decir compilador nos referimos al programa, y al decir compilación al proceso en sí. En esencia ambos términos cumplen con la definición más simple de un compilador, es decir, sea el programa compilador o el proceso de compilación, ambos reciben como entrada un código escrito en algún lenguaje y producen como salida otro código escrito en otro lenguaje.
Estructura de un Compilador:
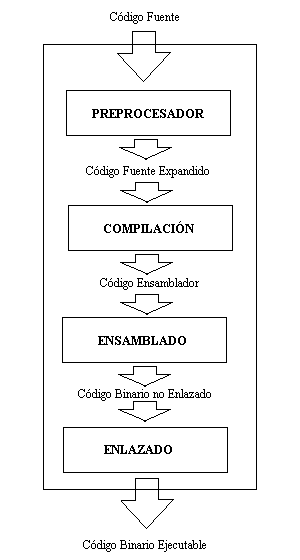
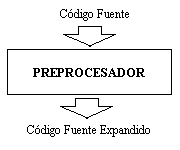
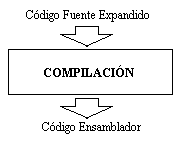
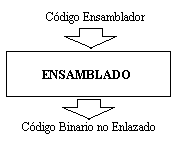
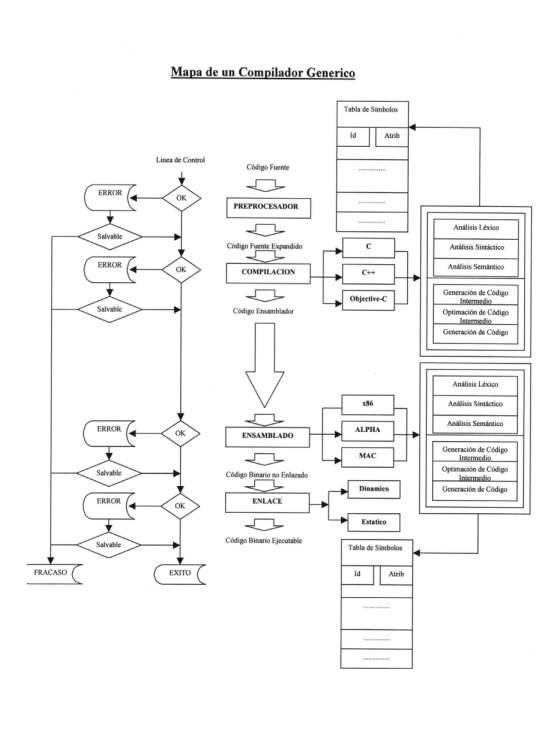
La estructura de un compilador, esta dividida en cuatro grandes módulos, cada uno independiente del otro, se podría decir que un compilador esta formado por cuatros módulos mas a su vez.El primero de ellos es el preprocesador, es el encargado de transformar el código fuente de entrada original en el código fuente puro. Es decir en expandir las macros, incluir las librerías, realizar un preprocesado racional (capacidad de enriquecer a un lenguaje antiguo con recursos más modernos), extender el lenguaje y todo aquello que en el código de entrada sea representativo de una abreviatura para facilitar la escritura del mismo. El segundo modulo es el de compilación que recibe el código fuente puro, este es él modulo principal de un compilador, pues si ocurriera algún error en esta etapa el compilador no podría avanzar. En esta etapa se somete al código fuente puro de entrada a un análisis léxico gráfico, a un análisis sintáctico, a un análisis semántico, que construyen la tabla de símbolos, se genera un código intermedio al cual se optimiza para así poder producir un código de salida generalmente en algún lenguaje ensamblador. El tercer modulo es el llamado modulo de ensamblado, este modulo no es ni más mi menos que otro compilador pues recibe un código fuente de entrada escrito en ensamblador, y produce otro código de salida, llamado código binario no enlazado. Si por un momento viéramos a este modulo como un programa independiente, veríamos que en este caso los términos programa compilador y proceso de compilación son los mismos. Pues este modulo no es mas que un compilador, que en su interior realiza como su antecesor un análisis léxico gráfico, un análisis sintáctico, un análisis semántico, crea una tabla de símbolos, genera un código intermedio lo optimiza y produce un código de salida llamado código binario no enlazado, y a todo este conjunto de tares se los denomina proceso de compilación. Como se puede ver este compilador (llamado ensamblador) a diferencia de los demás compiladores no realiza una expansión del código fuente original(código fuente de entrada), tiene solamente un proceso de compilación y por supuesto no enlaza el código fuente. Es un compilador que carece de los módulos de preprocesado y enlazado, y donde los módulos de compilación y ensamblado son los mismos. El cuarto y ultimo modulo es el encargado de realizar el enlazado del código de fuente de entrada (código maquina relocalizable) con las librerías que necesita, como así también de proveer al código de las rutinas necesarias para poder ejecutarse y cargarse a la hora de llamarlo para su ejecución, modifica las direcciones relocalizables y ubica los datos en las posiciones apropiadas de la memoria. Este ultimo modulo es el que produce como salida el código binario enlazado. Ya sea dinámico o estático, al decir dinámico se refiere a que el código producido utiliza librerías dinámicas (librerías ya cargadas en el sistema), esto implica que se obtendrá un código más corto y que se actualizara automáticamente si aparece alguna nueva versión de las librerías, mientras que el estático se refiere al echo que no se realiza enlace con ninguna librería y por lo tanto se obtendrá un código mas largo con una copia de las rutinas de librería que necesita. Estructura del proceso de Compilación:
Analizando en detalle el proceso de compilación, se divide en dos grandes fases, una de Análisis y la otra de Síntesis.
Fase de Análisis:
En el llamado análisis lexicográfico o léxico, el compilador revisa y controla que las "palabras" estén bien escritas y pertenezcan a algún tipo de token (cadena) definido dentro del lenguaje, como por ejemplo que sea algún tipo de palabra reservada, o si es el nombre de una variable que este escrita de acuerdo a las pautas de definición del lenguaje. En esta etapa se crea la tabla de símbolos, la cual contiene las variables y el tipo de dato al que pertenece, las constantes literales, el nombre de funciones y los argumentos que reciben etc.
En el análisis sintáctico como su nombre lo indica se encarga de revisar que los tokens estén ubicados y agrupados de acuerdo a la definición del lenguaje. Dicho de otra manera, que los tokens pertenezcan a frases gramaticales validas, que el compilador utiliza para sintetizar la salida. Por lo general las frases gramaticales son representadas por estructuras jerárquicas, por medio de árboles de análisis sintáctico. En esta etapa se completa la tabla de símbolos con la dimensión de los identificadores y los atributos necesarios etc.
El análisis semántico se encarga de revisar que cada agrupación o conjunto de token tenga sentido, y no sea un absurdo. En esta etapa se reúne la información sobre los tipos para la fase posterior, en esta etapa se utiliza la estructura jerárquica de la etapa anterior y así poder determinar los operadores, y operandos de expresiones y preposiciones.
Fase de Síntesis:
Etapa de generación de código intermedio, aunque algunos compiladores no la tienen, es bueno saber de su existencia, en esta etapa se lleva el código del programa fuente a un código interno para poder trabajar mas fácilmente sobre él. Esta representación interna debe tener dos propiedades, primero debe ser fácil de representar y segundo debe ser fácil de traducir al código objeto.
En la etapa de optimización de código, se busca obtener el código mas corto y rápido posible, utilizando distintos algoritmos de optimización.
Etapa de generación de código, se lleva el código intermedio final a código maquina o código objeto, que por lo general consiste en un código maquina relocalizable o código ensamblador. Se selecciona las posiciones de memoria para los datos (variables) y se traduce cada una de las instrucciones intermedias a una secuencia de instrucciones de maquina puro.
La tabla de símbolos no es una etapa del proceso de compilación, sino que una tarea, una función que debe realizar el proceso de compilación. En ella se almacenan los identificadores que aparecen en el código fuente puro, como así también los atributos de los mismos, su tipo, su ámbito y en el caso de los procedimientos el número de argumentos el tipo de los mismos etc. En otras palabras una tabla de símbolos es una estructura de datos, que contiene un registro por cada identificador, y sus atributos. La tabla de símbolo es accedida tanto para escritura como parar lectura por todas las etapas.
Detector de errores o manejador de errores, al igual que la tabla de símbolos no es una etapa del proceso de compilación, si no que es una función, muy importante, pues al ocurrir un error esta función debe tratar de alguna forma el error para así seguir con el proceso de compilación (la mayoría de errores son detectados en las etapas de análisis léxico, análisis sintáctico, análisis semántico).Supongamos que un compilador tiene que analizar la siguiente preposición:
Preposición: suma= var1 + var2 + 10;
Análisis Léxico
El analizador léxico lee los caracteres del programa fuente, y verifica que correspondan a una secuencia lógica (identificador, palabra reservada etc.). Esta secuencia de caracteres recibe el nombre componente léxico o lexema. En este caso el analizador léxico verifica si el identificador id1 (nombre interno para "suma") encontrado se halla en la tabla de símbolos, si no esta produce un error porque todavía no fue declarado, si la preposición hubiese sido la declaración del identificador "suma" en lenguajes C, C++ (int suma;) el analizador léxico agregaria un identificador en la tabla de símbolos, y así sucesivamente con todos los componentes léxicos que aparezcan.
id1= id2+ id3 * 10
Análisis Sintáctico
El analizador sintáctico impone una estructura jerárquica a la cadena de componentes léxicos, generada por el analizador léxico, que es representada en forma de un árbol sintáctico.
=
/ \
id1 +
/ \
id2 +
/ \
id3 10
Análisis Semántico
El analizador semántico verificara en este caso que cada operador tenga los operandos permitidos.
=
/ \
id1 +
/ \
id2 +
/ \
id3 tipo_ent
|
10
Generador de código intermedio
En esta etapa se lleva la preposición a una representación intermedia como un programa para una maquina abstracta.
temp1= tipo_ent(10)
temp2= id3 * temp1
temp3= id2 + tem2
id1= temp3
Optimización de código
El código intermedio obtenido es representado de una forma mas optima y eficiente.
temp1= id3 * 10.0
id1= id2 + temp1
Generador de código
Finalmente lleva el código intermedio a un código objeto que en este caso es un código relocalizable o código ensamblador (también llamado código no enlazado).
MOVF id3, R2
MULT #10.0, R2
MOVF id2, R1
ADDF R2, R1
MOVF R1, id1
Este el código objeto obtenido que es enviado al modulo de ensamblado. Para entender todo esto veamos un ejemplo utilizando como lenguaje en este caso al popular lenguaje de programación C creado por Kernighan y Ritchie. El siguiente código esta definido de acuerdo al standard ANSI C.
- #include<stdio.h>
void main()
{
char* frase= " Hola Mundo...!!!";
printf("%s", frase );
};
En la primer línea se encuentra una directiva de preprocesador, esta línea le indica al compilador que tiene que incluir la librería stdio.h, es decir transformar el código fuente de entrada en el código fuente puro (expandido).
Al pasar por él modulo de preprocesado, el código fuente queda de la siguiente manera.
# 1 "hmundo.c"
# 1 "c:/compilador/include/stdio.h" 1 3
# 1 " c:/compilador/include/sys/types.h" 1 3
# 12 " c:/compilador/include/stdio.h" 2 3
typedef void *va_list;
typedef long unsigned int size_t;
typedef struct {
int _cnt;
char *_ptr;
char *_base;
int _bufsiz;
int _flag;
int _file;
char *_name_to_remove;
} FILE;
typedef unsigned long fpos_t;
extern FILE __stdin, __stdout, __stderr;
void clearerr(FILE *_stream);
int fclose(FILE *_stream);
int feof(FILE *_stream);
int ferror(FILE *_stream);
int fflush(FILE *_stream);
int fgetc(FILE *_stream);
int fgetpos(FILE *_stream, fpos_t *_pos);
char * fgets(char *_s, int _n, FILE *_stream);
FILE * fopen(const char *_filename, const char *_mode);
int fprintf(FILE *_stream, const char *_format, ...);
int fputc(int _c, FILE *_stream);
int fputs(const char *_s, FILE *_stream);
size_t fread(void *_ptr, size_t _size, size_t _nelem, FILE *_stream);
FILE * freopen(const char *_filename, const char *_mode, FILE *_stream);
int fscanf(FILE *_stream, const char *_format, ...);
int fseek(FILE *_stream, long _offset, int _mode);
int fsetpos(FILE *_stream, const fpos_t *_pos);
long ftell(FILE *_stream);
size_t fwrite(const void *_ptr, size_t _size, size_t _nelem, FILE *_stream);
int getc(FILE *_stream);
int getchar(void);
char * gets(char *_s);
void perror(const char *_s);
int printf(const char *_format, ...);
int putc(int _c, FILE *_stream);
int putchar(int _c);
int puts(const char *_s);
int remove(const char *_filename);
int rename(const char *_old, const char *_new);
void rewind(FILE *_stream);
int scanf(const char *_format, ...);
void setbuf(FILE *_stream, char *_buf);
int setvbuf(FILE *_stream, char *_buf, int _mode, size_t _size);
int sprintf(char *_s, const char *_format, ...);
int sscanf(const char *_s, const char *_format, ...);
FILE * tmpfile(void);
char * tmpnam(char *_s);
int ungetc(int _c, FILE *_stream);
int vfprintf(FILE *_stream, const char *_format, va_list _ap);
int vprintf(const char *_format, va_list _ap);
int vsprintf(char *_s, const char *_format, va_list _ap);
int fileno(FILE *_stream);
FILE * fdopen(int _fildes, const char *_type);
int pclose(FILE *_pf);
FILE * popen(const char *_command, const char *_mode);
extern FILE _stdprn, _stdaux;
void _stat_describe_lossage(FILE *_to_where);
int _doprnt(const char *_fmt, va_list _args, FILE *_f);
int _doscan(FILE *_f, const char *_fmt, void **_argp);
int _doscan_low(FILE *, int (*)(FILE *_get), int (*_unget)(int, FILE *), const char *_fmt, void **_argp);
int fpurge(FILE *_f);
int getw(FILE *_f);
int mkstemp(char *_template);
char * mktemp(char *_template);
int putw(int _v, FILE *_f);
void setbuffer(FILE *_f, void *_buf, int _size);
void setlinebuf(FILE *_f);
char * tempnam(const char *_dir, const char *_prefix);
int _rename(const char *_old, const char *_new);
# 1 "hmundo.c" 2
void main()
{
char* frase= " Hola Mundo...!!!";
printf("%s", frase );
};
El nuevo código contiene el encabezado o prototipo de la/s función/es que se encuentran en el archivo de cabecera stdio.h, y que serán posiblemente utilizadas en el código fuente original. Este código es pasado al modulo de compilación quien luego de analizarlo y verificar si se encuentra correcto, transformara el código fuente puro (expandido) en código ensamblador y lo envía al modulo de ensamblado.
.file "hmundo.c"
compiler_compiled.:
___compiled_c:
.text
LC0:
.ascii " Hola Mundo...!!!\0"
LC1:
.ascii "%s\0"
.align 2
.globl _main
_main:
pushl %ebp
movl %esp,%ebp
subl $4,%esp
call ___main
movl $LC0,-4(%ebp)
movl -4(%ebp),%eax
pushl %eax
pushl $LC1
call _printf
addl $8,%esp
L1:
leave
ret
Este código será analizado por él modulo de ensamblado, que lo llevara a código binario no enlazado, y lo enviara al modulo de enlazado. El código de salida enviado al modulo de enlazado es el siguiente.
- L�³Ú(7ô�.text�
@�Œ�Ì�� �
.............
.data�@�@�@�
.bss�@�@�€
Hola Mundo...!!!�%s�v�
U‰åƒìèÝÿÿÿÇEü�‹EüPh�
èÈÿÿÿƒÄ ÉÃv�.file�þÿ�
ghmundo.c����.
.............
_main����
___main��
_printf��%�
_compiled.�
___compiled_c�Finalmente él modulo de enlazado, vincula el código binario sin enlazar con las librerías dinámicas necesarias según sea el caso o no. Y produce como salida el código binario enlazado o código binario ejecutable.
- MZ�� �'�ÿÿ�`�T�
$Id: xxx.asm built mm/dd/aa 00:00:00 by ...asm $
@(#) xxx.asm built mm/dd/aa 00:00:00 by ...asm
.............
]v� Hola Mundo...!!!�%s�v�
U‰åƒìèý �ÇEüx"‹EüPhŠ"è, �ƒÄ ÉÃv�387
No �80387 detected.
Warning: Coprocessor not present and DPMI setup failed!
If application attempts floating operations system may hang!
¸'�ÉÃv�¸"�ÉÃCall frame traceback EIPs:
0x�
0x�
Alignment Check�Coprocessor Error�Page fault�General Protection Fault�Stack
Fault�Segment Not Present�Invalid TSS�Coprocessor overrun�Double
............
Division by Zero�: sel=� invalid� base=� limit=�v�U‰åƒìS‹]jÿu jè?�
............
Este es el código final conocido como código maquina. e-mail: gdit@bbs.frc.utn.edu.ar
|
|