Desarrollo de un Sistema de Gestión de Base de Datos
Relacional.
TecnoDB
Universidad Tecnológica Nacional
Facultad Córdoba
Laboratorio de Investigación de Software
Departamento de Ingeniería en Sistemas
de Información
Anabel Natalia Ruiz
Ing. César Ignacio Martínez Spessot
Ing. Juan Carlos Vázquez
Ing. Calixto Maldonado
Dirección Postal
Universidad Tecnológica
Nacional - Facultad Regional Córdoba
Maestro M. López esq. Cruz
Roja Argentina
Ciudad Universitaria - C.P.
(5016)
Córdoba - República
Argentina.
Dirección Electrónica
anabelru@bbs.frc.utn.edu.ar
cspessot@sistemas.frc.utn.edu.ar
jcvazquez@sistemas.frc.utn.edu.ar
calixto@bbs.frc.utn.edu.ar
Resumen
Los estudios de los Sistemas de Gestión de
Base de Datos Relacionales y las bases de Datos constituyen hoy en día el
eslabón principal de investigación en grandes empresas y universidades de todo
el mundo. La creación de un motor de base de datos sigue siendo un reto ya que
siguen existiendo aspectos en los cuales no se han logrado una solución
definitiva. Por ejemplo, los requerimientos de almacenamiento de imágenes,
vídeo, sonido, etc.
El propósito de este proyecto es
implementar un administrador de bases de datos relacional y un intérprete de
lenguaje de consulta de datos que se pueda utilizar en investigación y
desarrollo de Sistemas Informáticos. Es importante contar un SGBD desarrollado
en nuestras universidades al cual se le puedan hacer modificaciones, lo cual es
prácticamente imposible con los productos comerciales debido a que no está
disponible: su código fuente, documentación y
sobre todo capacitación.
Nuestra investigación conduce al
desarrollo de innovadores algoritmos para
acceso y mantenimiento de los datos y procedimientos.
Introducción
Una Base de Datos (BD)[1], es en esencia
una colección de información que existirá en un período de tiempo, información que
es administrada por un SMBD. Ullman y Widom [1], también establecen que un
Sistema Administrador de Bases de Datos debe:
w
Permitir a los usuarios crear nuevas bases de datos y especificar
su esquema (estructura lógica de los datos), usando un lenguaje
especializado llamado un Lenguaje de Definición de Base de Datos
w
Dar a los usuarios la habilidad de consultar los datos (una
consulta es una respuesta de la base de datos a una cuestión sobre los datos) y
modificar los datos, usando un lenguaje apropiado, a menudo llamado un Lenguaje
de Consulta o Lenguaje de Manipulación de Datos.
w
Soportar el almacenamiento de una gran cantidad de datos sobre un
gran período de tiempo, guardando la seguridad en un accidente o un uso no
autorizado y permitir el acceso eficiente a los datos para las consultas o
modificaciones a la base de datos.
w
Controlar los accesos a los datos en forma simultanea de varios
usuarios, sin permitir que las acciones de uno afecten las de otros usuarios y
sin permitir que accesos simultáneos dañen la organización a los propios datos.
Estos son los principales objetivos de
nuestra investigación. En la cual al principio comenzó con la definición de un
esquema y un lenguaje que permita realizar la definición y consulta de base de
datos.
El Lenguaje implementado para la
comunicación fue el SQL por lo que diseñamos su sintaxis mediante el Formalismo
de Backus Naur (BNF).
Actualmente nuestro punto de concentración
es implementar un administrador de base de datos funcionalmente completo para
soportar almacenamiento de grandes cantidades de datos, tener un módulo de
comunicación a través de red, driver o librería para acceso a la base de datos
desde otro lenguaje y acceso concurrente.
Arquitectura
de TecnoDB
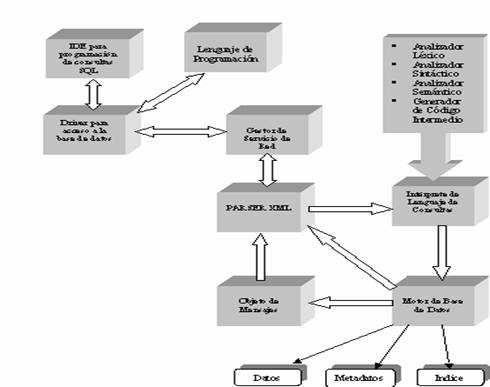
Los principales componentes del Sistema Administrador de Base de
Datos son:
§ IDE de Desarrollo de Consultas
§
Driver para acceso a la base de datos
§ Gestor de Servicios de Red
§
Parser XML
§
Objetos de Mensaje
§
Intérprete de Lenguaje de Consultas
§
Motor de Base de Datos
Se desarrolló un IDE de Desarrollo de Consultas con el fin de que el usuario del motor tuviese un framework con quien interactuar sin necesidad de implementar la consulta en un lenguaje de programación. El encapsular en un componente el IDE de Desarrollo nos permitió poder ser reemplazado por otro el cual es el driver para acceso a la base de datos, esto es necesario para integrar el motor con otros lenguajes (y así embeber el lenguaje SQL) como por ejemplo C++Builder, Visual C++, C#, Java, Kylix.
El IDE de Desarrollo envía el código del
programa al Driver de Acceso a
Una vez que ha llegado la consulta en XML
es enviada al Parser para que entregue la consulta (consulta sola sin tag´s del
XML) en lenguaje SQL al Intérprete de Lenguaje de Consultas con el objetivo de
que éste realice el Análisis Léxico, Sintáctico y Semántico correspondiente,
por último y en caso que no exista ningún error, traduce a código
base del Motor. Si en el transcurso de los diferentes análisis hubo un error
inmediatamente se informa del mismo al Objeto de Mensajes.
Con el código Base, el Motor de Base de Datos realiza la petición correspondiente y si no hubo ningún error el resultado es transformado a XML y transmitido al Gestor de Servicios quién por último lo enviará a travéz del protocolo TCP/IP al cliente para su posterior visualización de resultado al usuario (si se utiliza el IDE de Desarrollo) o procesamiento (en caso de que se use un lenguaje de programación). Cabe destacar que si la ejecución de alguna instrucción genera un error, dicho problema es enviado al Objeto de Mensajes quien informa el tipo de error y descripción.
Se observa entonces que el lenguaje de
alto nivel de la base de datos es XML. El motor recibe XML (consultas) y envía
los datos a través de XML (resultados y errores). Hemos elegido XML como formato de transmisión universal para
garantizar la interoperabilidad siempre que el componente receptor se ejecute en
una plataforma donde haya un intérprete XML que proporcione un número
significativo de funciones. El Extensible
Markup Language (XML) es un
estándar basado en texto sencillo pero eficaz que tiene un amplio reconocimiento
en la industria, es común encontrar un intérprete XML en casi cualquier
plataforma. Por ello, estamos convencidos que el componente receptor no tendrá
ninguna restricción de arquitectura.
En cuanto al motor se poseen tres archivos
por cada tabla: uno de metadatos, otro de datos y por último uno de índices.
Los índices utilizados para la recuperación eficiente de la información y están
implementados en árboles B+ y/o digital que pueden ser usado indiferentemente.
El
Intérprete de TecnoDB
El intérprete se divide en dos fases: una
parte que analiza la entrada y genera estructuras intermedias y otra parte que
sintetiza la salida.
Fase de Análisis * Lexicográfico
* Sintáctico
* Semántico
Fase de Síntesis * Generación de código intermedio
* Optimización de
código
*
Generación de código del motor.
Los objetivos
propuestos para la fase de análisis son: controlar la corrección de programa
fuente y generar estructuras intermedias necesarias para comenzar la síntesis.
Para llevar a cabo esto, el Análisis cuenta con los tres tipos de análisis
antes citados.
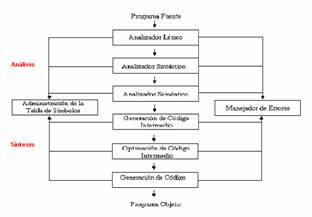
Figura 1:
Fases del intérprete TecnoDB
Analizador
Léxico
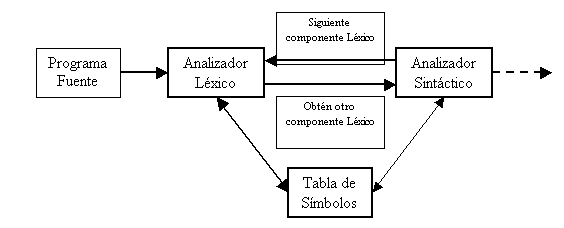

La principal función consiste en leer los
caracteres de entrada, reconocer las piezas debido a la relación con la tabla
de símbolos y elaborar como salida una secuencia de componentes léxicos que
utiliza el analizador sintáctico para hacer el análisis.
Funciones que realiza:
- Leer los caracteres de la entrada
- Generar una secuencia de componentes léxicos (TOKENS)
- Eliminar los comentarios del programa, espacios en blanco,
tabuladores, retorno de carro, etc, y en general, todo aquello que carezca
de significado según la sintaxis del lenguaje.
- Reconocer los identificadores de usuario, números, palabras
reservadas del lenguaje, y tratarlos correctamente con respecto a la tabla
de símbolos (solo en los casos que debe de tratar con la tabla de
símbolos).
- Llevar la cuenta del número de línea por la que va leyendo,
por si se produce algún error, dar información sobre donde se ha
producido.
- Avisar de errores léxicos. Por ejemplo, si @ no pertenece al
lenguaje, avisar de un error.
Analizador Sintáctico


Es la fase de análisis sintáctico se lleva
a cabo el chequeo del texto de entrada en base a una gramática dada. Y en caso
de que el programa de entrada sea válido, suministra el árbol sintáctico que lo
reconoce.
En teoría, se supone que la salida del
analizador sintáctico es alguna representación del árbol sintáctico que
reconoce la secuencia de tokens suministrada por el analizador léxico.
Funciones que realiza:
- Comprobar que la secuencia de componentes léxicos cumple las
reglas de la gramática
- Generar el árbol sintáctico
- Generar errores cuando se producen.
- Generar código intermedio.
Analizador Semántico
Funciones que realiza:
- Comprobación de tipos: La aplicación de los operadores y
operandos deben ser compatibles
- Comprobaciones del flujo del control: Las proposiciones que hacen
que se abandone el flujo del control de una construcción debe transferirse
a otro punto. (break, exit)
- Comprobaciones de unicidad: Hay situaciones en los que un
objeto solo puede definirse una vez exclusivamente. Las etiquetas de una
sentencia case no deben repetirse, declaraciones de objetos
- Comprobaciones relacionadas con nombre: El mismo nombre debe
aparecer dos o más veces.
- Además de comprobar que un programa cumple con las reglas de
la gramática, hay que comprobar que lo que se quiere hacer tiene sentido
- Esta fase también modifica la tabla de símbolos y suele estar
mezclada con la generación de código intermedio
Generación
de Código Base del Motor
En esta etapa se convierte la salida del
Análisis en un código que entienda el motor. TecnoDB está trabando con una
estructura para cada sentencia que luego será tomados como parámetros por
funciones miembros de un objeto llamado Ejecutor de Instrucciones.
G
Cada proceso que se desea comunicar con otro se identifica en la pila de protocolos TCP/IP con uno o más puertos. Un puerto es un número de 16 bits, empleado por un protocolo host – a – host para identificar a que protocolo del nivel superior o programa de aplicación se deben entregar los mensajes recibidos.
Como algunas aplicaciones son ya de por sí protocolos estandarizados, como TELNET y FTP, emplean el mismo número de puerto en todas las implementaciones TCP/IP. Estos puertos "asignados" se conocen como puertos bien conocidos, y a sus aplicaciones, aplicaciones bien conocidas.
Estos puertos son controlados y asignados por IANA
("Internet Assigned Numbers Authority") y en la mayoría de los
sistemas sólo los puede utilizar los procesos del sistema o los programas que
ejecutan usuarios privilegiados. Ocupan número de puerto comprendidos en el
rango de
La confusión que se produce cuando dos aplicaciones distintas intentan usar los mismos puertos en un host se evita haciendo que soliciten un puerto disponible a TCP/IP. Como este número se asigna dinámicamente, puede ser diferente en cada ejecución de una misma aplicación.
UDP, TCP y ISO TP-4 están todos basados en el mismo principio de uso de los puertos (Ver Figure - UDP, A Demultiplexer Based on Ports y Figure - TCP Connection.) En la medida de lo posible, se usan los mismos números para los servicios situados sobre UDP, TCP y ISO TP-4.
Zocalox
En primer lugar, conviene definir los siguientes términos:
· Un zócalo es un tipo especial de descriptor de fichero que un proceso usa para solicitar servicios de red al sistema operativo.
· Una dirección de zócalos es la tripleta:
{protocolo, dirección local, proceso local }
En la pila TCP/IP, por ejemplo:
{tcp, 193.44.234.3, 12345}
· Una conversación es el enlace de comunicaciones entre dos procesos.
· Una asociación es la quíntupla que especifica completamente los dos procesos comprendidos en una conexión:
{protocolo, dirección local, proceso - local, dirección exterior, proceso exterior}
En la pila TCP/IP, por ejemplo:
{tcp, 193.44.234.3, 1500, 193.44.234.5, 21}
podría ser una asociación válida.
· Una medio – asociación es:
{protocolo, dirección - local, proceso local }
o
{protocolo, dirección exterior, proceso exterior}
que especifican cada una de las mitades de la conexión.
· La medio – asociación se denomina también zócalo o dirección de transporte. Es decir, un zócalo es un punto terminal para la comunicación que puede ser nombrado y direccionado en una red.
La interfaz del zócalo es una de tantas APIs con los protocolos de comunicación. Se introdujo por primera vez en el UNIX BSDD 4.2. Aunque no ha sido estandarizada, se ha convertido en un estándar de facto.
4.2BSD permitía dos dominios de comunicación distintos: Internet y UNIX. 4.3BSD ha añadido los protocolos del XNS ("Xerox Network System") y 4.4BSD añadirá una interfaz extendida para soportar los protocolos OSI.
Implementación de TecnoDB
La implementación del motor se ha realizado en el lenguaje C++.
Se permite definir varios tipos de campos: carácter, fecha, entero, lógico,
flotante y binario. Este último esta preparado para guardar imágenes, video,
sonido u otro programa ejecutable.
La estructura del archivo de metadato se realiza de la siguiente manera:
struct metadato
{ char
nombre [30]; //Nombre del campo
int tipo; //Tipo de campo: 1-fecha,
2-carácter,etc. Según enum del encabezado
int
enteros; //Tamaño de
longitud del campo
int
decimales; //Tamaño del
longitud de la parte decimal (usado solamente en flotante)
bool
esclave; //Identificador si
es un campo clave
};
Como se puede observar el tamaño máximo para un nombre de un campo es de
30 caracteres. Con el archivo de metadatos en memoria se puede levantar el
archivo de datos el cual es almacenado por bytes sin una estructura
predeterminada.
El Sistema maneja tres archivos básicos para almacenar, recuperar y
modificar los datos y la estructura de la tabla los cuales son: archivo de
datos, metadatos y procedimientos o programas.
Además se ha incorporado dos tipos de índices a elección según el tipo
de datos que se desea ordenar y buscar a saber: árbol B+, árbol digital.
La interfaz del motor cuenta con una serie de ventanas para una correcta
edición, interpretación, y corrección de errores de las sentencias SQL. Figura
5.
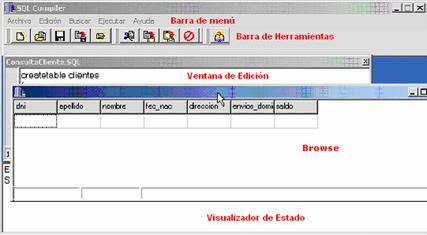
Figura 5: Interfaz del Motor de base de datos
Cuando tenemos una sentencia SELECT, los registros que cumplen con las
condiciones estipuladas en el WHERE, se muestran en una nueva ventana, el
Browse, que contiene la tabla con los campos seleccionados, sus respectivos
nombres y el listado de los registros elegidos, la visualización de la misma es
en forma de cuadrícula o grilla
El Visualizador de Estado del programa, situado al pie de la ventana,
muestra mensajes de los errores encontrados (indicando posición y tipo de
error) y las acciones realizadas (por ejemplo: se han borrado tres registros;
se ha creado la tabla, etc.). Este sirve para localizar fácilmente los errores
cometidos y proceder a su corrección.
Para ilustrar el funcionamiento del motor mostramos un pequeño ejemplo
en
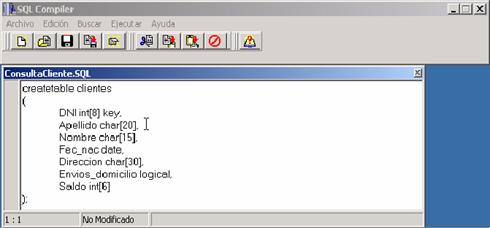
Figura 6: Ejemplo de creación
de un tabla en la base de datos
El ejemplo mostrado es una sentencia para crear una tabla en la base de
datos; la hemos diseñado con una sintaxis parecida a la creación de una clase
en C++.
En la definición de los campos de la tabla se tiene que especificar el
tipo de dato, la extensión y si el campo es clave o no.
Inmediatamente después de iniciar la ejecución del código, comienza a funcionar
el intérprete de consultas, el mismo va examinando cada sentencia y la analiza
léxica, sintáctica y semánticamente. Cuando concluye con dicho análisis,
aparece un mensaje señalando que el programa es léxica, sintáctica y
semánticamente correcto.
En caso de que encuentre un error, el intérprete lo imprime en el
visualizador de estado; lo mismo hace cuando actualiza una tabla, ya sea por
borrado, selección, modificación o inserción de registros.
En la figura 7 se ejemplifica una serie de instrucciones insert y
posteriormente una consulta a toda la tabla de clientes. Como se puede observa,
la sintaxis de éstas sentencias son similares a las de cualquier lenguaje SQL,
cabe destacar que nos hemos guiado, para el diseño del parser, del SQL ASNI; es
requerido que al final de cada sentencia se deba colocar un punto y coma (;)
para establecer el fin de la instrucción.
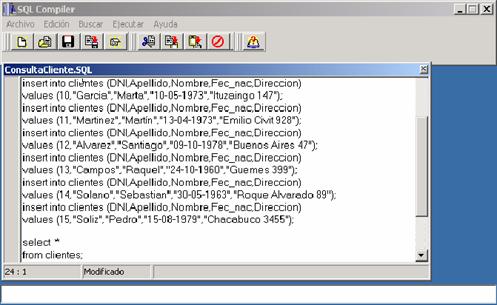
Figura 7: Ejemplo de inserción de registros y consulta de los mismos.
En
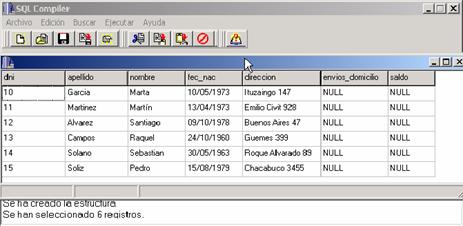
Figura 8: Resultado de la consulta de la tabla clientes.
La figura 9 es un ejemplo de borrado de un registro, destacando que el
registro debe cumplir con la condición que manifiesta el where. La siguiente
instrucción hace referencia a una inserción violando la integridad referencial
de la tabla; por ello el sentido del siguiente select; que es para comprobar
que no se haya modificado el registro y que realmente no se haya ingresado un
registro con el mismo número de clave. Después de la ejecución, se puede
apreciar en el visualizador de mensajes los accesos y errores que se hayan
producido. Veamos el ejemplo:
-
El primer mensaje viene a colación del
select que se ha realizado a toda la tabla de clientes, comentado en el párrafo
anterior.
-
El segundo informa sobre el borrado del
registro que tiene el número de documento igual a 11.
-
El tercero notifica sobre el error
producido al querer ingresar un registro con un número de clave repetido, con
el objetivo de mantener la unicidad de la clave primaria y la integridad
referencial.
-
El cuarto comunica la selección de un
registro. La instrucción select se ha hecho con la intención de demostrar que
realmente el registro permanezca inalterado, mientras que el intento de nueva
inserción no pueda llevarse a cabo y justamente se exhiba el error pertinente.
-
El último mensaje manifiesta que el
programa (o sea el archivo con extensión .sql) es léxica, sintáctica y
semánticamente correcto; esto quiere decir que el programa ha pasado por los
tres analizadores del intérprete y los mismos corresponden con el vector de
piezas del lenguaje (ver Anexo B), el parser, la lista de objetos
dinámicas, etc..
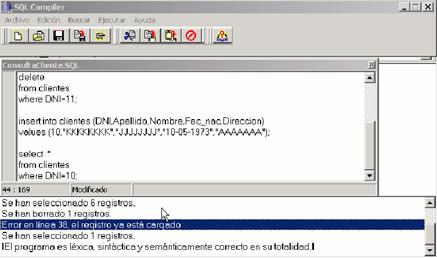
Figura 9: Ejemplo de borrado y unicidad de clave primaria.
Resumen
Los estudios de los
Sistemas de Gestión de Base de Datos Relacionales y las bases de Datos
constituyen hoy en día el eslabón principal de investigación en grandes
empresas y universidades de todo el mundo. La creación de un motor de base de
datos sigue siendo un reto ya que siguen habiendo aspectos en los cuales no se
han logrado una solución definitiva. Por ejemplo, los requerimientos de
almacenamiento de imágenes, vídeo, sonido, etc.
El propósito de este
proyecto es implementar un administrador de bases de datos relacional y un
intérprete de lenguaje de consulta de datos que se pueda utilizar en
investigación y desarrollo de Sistemas Informáticos. Es importante contar un
SGBD desarrollado en nuestras universidades al que se le puedan hacer
modificaciones, lo cual es prácticamente imposible con los productos
comerciales debido a que no está disponible: su código fuente, documentación y
capacitación.
Nuestra investigación
incluye el desarrollo de innovadores algoritmos para acceso y mantenimiento de los datos y procedimientos.
TecnoDB permite construir y manejar bases de datos
estructuradas y no numéricas, por ejemplo bases de datos cuyo mayor
constituyente es texto.
En los términos más generales, se puede pensar en una base
de datos de CDS/ISIS como un archivo o data relacionada que se recolecta para
satisfacer un determinado requerimiento de información de una comunidad. Cada
unidad de información se almacena en una base de datos que consiste de
elementos discretos o cuantificables, cada uno conteniendo una característica
particular de la entidad. Por ejemplo, una base de datos de una hemeroteca contendrá información sobre revistas, artículos, editoriales, etc. Cada unidad incluirá, en este caso,
datos de autor, título, fecha de publicación, precio, etc. Los datos son
almacenados en campos, a cada uno de los cuales se les asigna un
nombre indicativo de su contenido.
La colección de campos que contienen los datos de una unidad
de información dada se llama registro.
La característica exclusiva de TecnoDB es que está
especialmente diseñada para manejar campos ( y por consiguiente registros) de
amplitud variables, lo cual permite por un lado, una óptima utilización del
espacio de almacenamiento del disco, y por otro lado, una completa libertad en
la definición del ancho de cada campo.
Funciones del Sistema
Las funciones principales, proporcionadas por TecnoDB,
permiten:
· Definir Bases de Datos conteniendo la data requerida
· Definir estructuras de tablas según los requerimientos
· Definir el diccionario de metadatos
· Definir extensión de campos
· Ingresar nuevos registros en una base de datos dada.
· Modificar, corregir o borrar registros existentes.
· Automáticamente construir y mantener un rápido acceso a
archivos para cada base de datos con el fin de maximizar el tiempo de
recuperación de la data.
· Mostrar los registros o porciones de los mismos, de
acuerdo con sus requerimientos.
Conclusión
Las bases de datos son
una parte fundamental de los Sistemas de Información, las mismas se consideran
la piedra angular para el buen funcionamiento de las instituciones modernas
además de la rápida adaptabilidad a los
cambios del medio ambiente y procesos de negocios tales como servucción,
logística, toma de decisiones estratégicas, etc.
Argentina gasta año con
año enormes cantidades de dinero en la adquisición de este tipo de tecnologías,
sin que se vislumbre a corto o mediano plazo la creación de un Motor de Bases
de Datos Relacional hecho en nuestro país, funcionalmente completo, que aporte
conocimiento a nuestras universidades, que soporte la administración de
información de nuestras organizaciones y que ayude a evitar la fuga de divisas
en esta materia. Desafortunadamente, con excepción de los países altamente
desarrollados, los demás países solamente se han contentado con el papel de
consumidores de la tecnología de bases de datos.
Hemos implementado un
motor en lenguaje C++
nos posibilitará:
- El Disponer un manejador de bases de datos
de alta calidad que les permita a las instituciones participantes realizar
investigación y desarrollo que no se podrían hacer con manejadores
comerciales.
- Formar recursos humanos que requerirá
el país en la tecnología de bases de datos, almacenes de datos y búsqueda
de información para inteligencia de negocios.
- Elevación del nivel académico en el
área de bases de datos, al poner a disposición de todas las universidades
el manejador en forma gratuita.
- Creación de nuevas tecnologías para
almacenamiento, consulta, indización, etc.
Bibliografía:
Word Wide
Web Consortium, Julio 2003. http://www.w3.org/XML/